Q: Why does RelStorage support a SQLite backend? Doesn’t that defeat
the point?
A: The SQLite backend fills a gap between FileStorage and an
external RDBMS server.
FileStorage is fast, requires few resources, and has no external
dependencies. This makes it well suited to small applications,
embedded applications, or applications where resources are
constrained or ease of deployment is important (for example, in
containers).
However, a FileStorage can only be opened by one process at a time.
Within that process, as soon as a thread begins committing, other
threads are locked out of committing.
An external RDBMS server (e.g., PostgreSQL) is fast, flexible and
provides lots of options for managing backups and replications and
performance. It can be used concurrently by many clients on many
machines, any number of which can be committing in parallel. But
that flexibility comes with a cost: it must be setup and managed.
Sometimes running additional processes complicates deployment
scenarios or is undesirable (for example, in containers).
A SQLite database combines the low resource usage and deployment
simplicity of FileStorage with the ability for many processes to
read from and write to the database concurrently. Plus, it’s
typically faster than ZEO. The tradeoff: all processes using the
database must be on a single machine on order to share memory.
Q: Why is adding or updating new objects so slow?
A: If the database has grown substantially, it’s possible that
sub-optimal query plans are being used. Try to connect to the
database using the sqlite3 command line tool and issue the
ANALYZE command to
gather statistics for the database query optimizer.
When RelStorage creates a new SQLite database, it pre-populates
statistics to produce fast query plans. Over time
those might become incorrect.
To combat this, RelStorage issues PRAGMA OPTIMIZE when
connections are closed, but that doesn’t always work (the database
may be locked by another connection.
RelStorage issues the ANALYZE command automatically when the
database is packed.
Q: What maintenance does SQLite require?
A: Not much. If the database changes substantially, you might need
to ANALYZE it for best performance. If lots of objects are
added and removed, you may want to VACUUM it.
Q: Why is the SQLite database constrained to processes on a single
machine?
A: RelStorage uses SQLite’s write-ahead log (wal) to implement concurrency
and MVCC. This requires all processes using the database to be able
to share memory.
Q: What level of concurrency does SQLite support? Does it allow
parallel commits?
A: When RelStorage is used with SQLite, concurrent reads are always
supported with no limit.
However, SQLite only allows one connection to write to a database
at a time. It does not support the object-level locks as used by
the other databases in RelStorage 3+. Most of the work RelStorage
does during commit goes into a temporary database, though, and the
database is locked as close to the end of the commit process as
possible.
Note that packing a SQLite database makes no effort to reduce the
amount of time spent writing to the database. It’s unlikely you’ll
get meaningful parallel writes to happen while packing the
database. If you plan to deploy SQLite databases to production,
also plan to schedule downtime to pack them.
Q: Should I disable RelStorage’s cache when used with SQLite?
A: Possibly (with cache-local-mb0). Let the operating system
cache the SQLite data file instead. Depending on the operating
system, the resources of the machine, and what other processes are
running, this may result in an overall better use of memory while
still serving responses very quickly.
Q: What’s performance like?
Generally, overall it’s quite good compared to ZEO and not bad
compared to FileStorage. However, this is highly system-dependent.
Results of benchmarks have been much better on Linux systems than
on macOS. Some things, such as allocating new object IDs, are
slower.
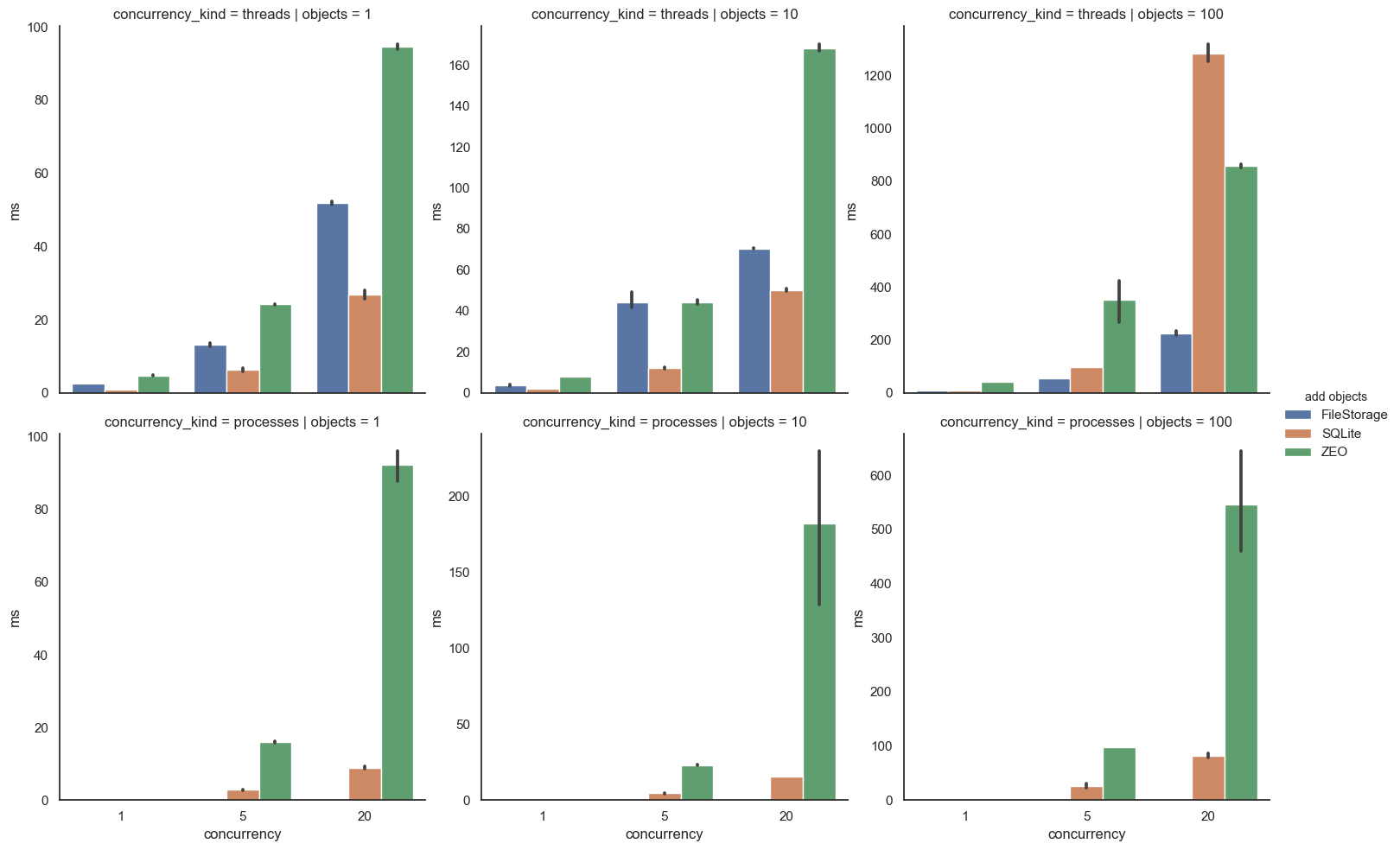
Here are some zodbshootout benchmark results comparing FileStorage,
a ZEO server using FileStorage running on localhost, and
RelStorage+SQLite. The standard benchmarks were run using 1, 5, and
20 concurrent readers or writers using threads of the same process,
or for ZEO and SQLite, separate processes. Transactions consisted
of 1, 10, or 100 objects.
The computer was a 2011 MacBook Pro that was otherwise mostly idle
running Gentoo Linux and tuned by pyperf for consistency.
In the graphs, the bars indicate time, so shorter bars are better,
and the centered vertical black lines are confidence intervals
(shorter ones of those indicate more predictable performance).
First, adding objects. SQLite wins every test (or at least
essentially ties FileStorage) except with 20 concurrent threads
adding 100 objects. This could be due to the ZEO networking code
releasing the GIL longer than SQLite, or due to the fact that
RelStorage currently has an extra temporary buffer copy involved.
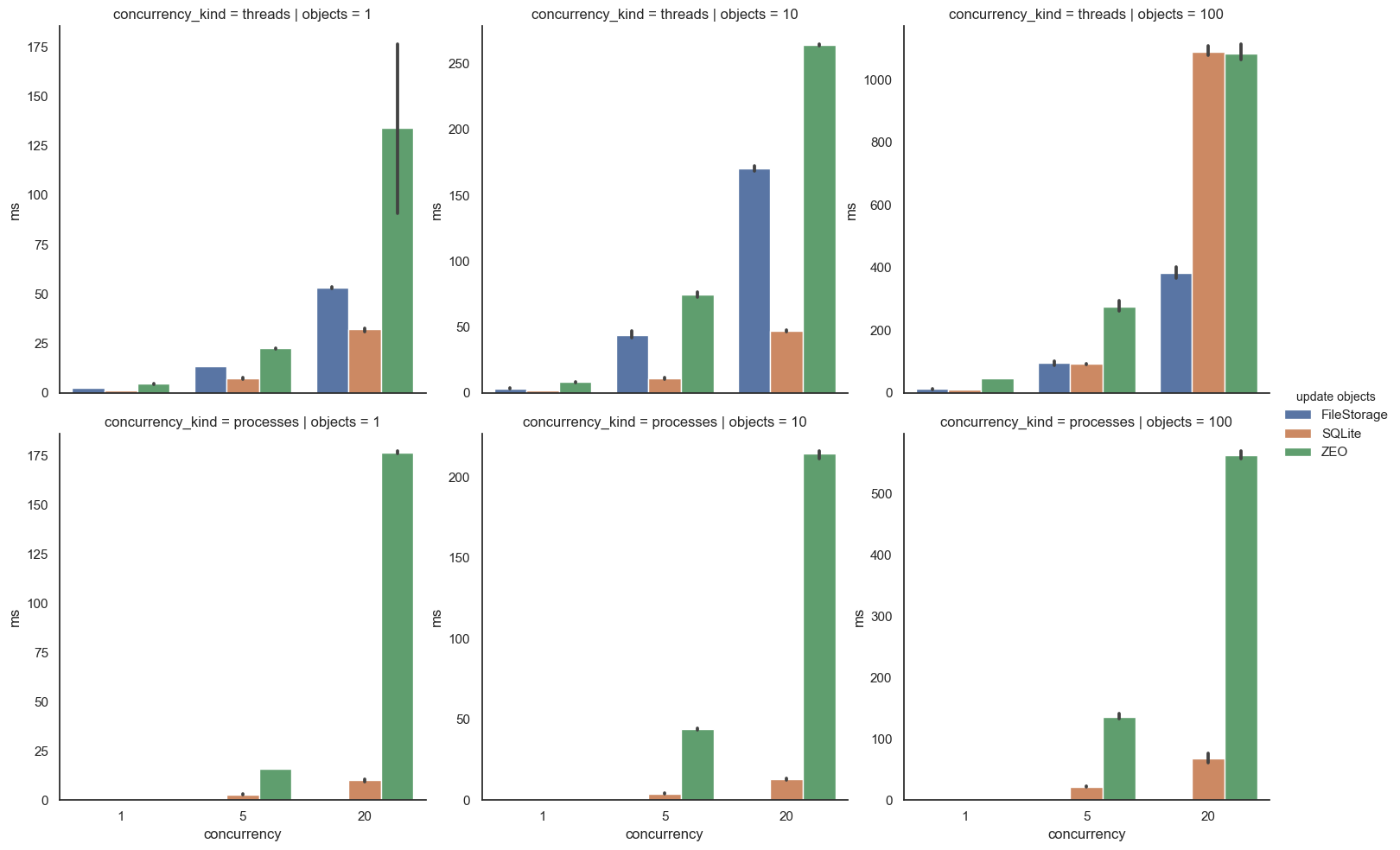
Updating existing objects is very similar.
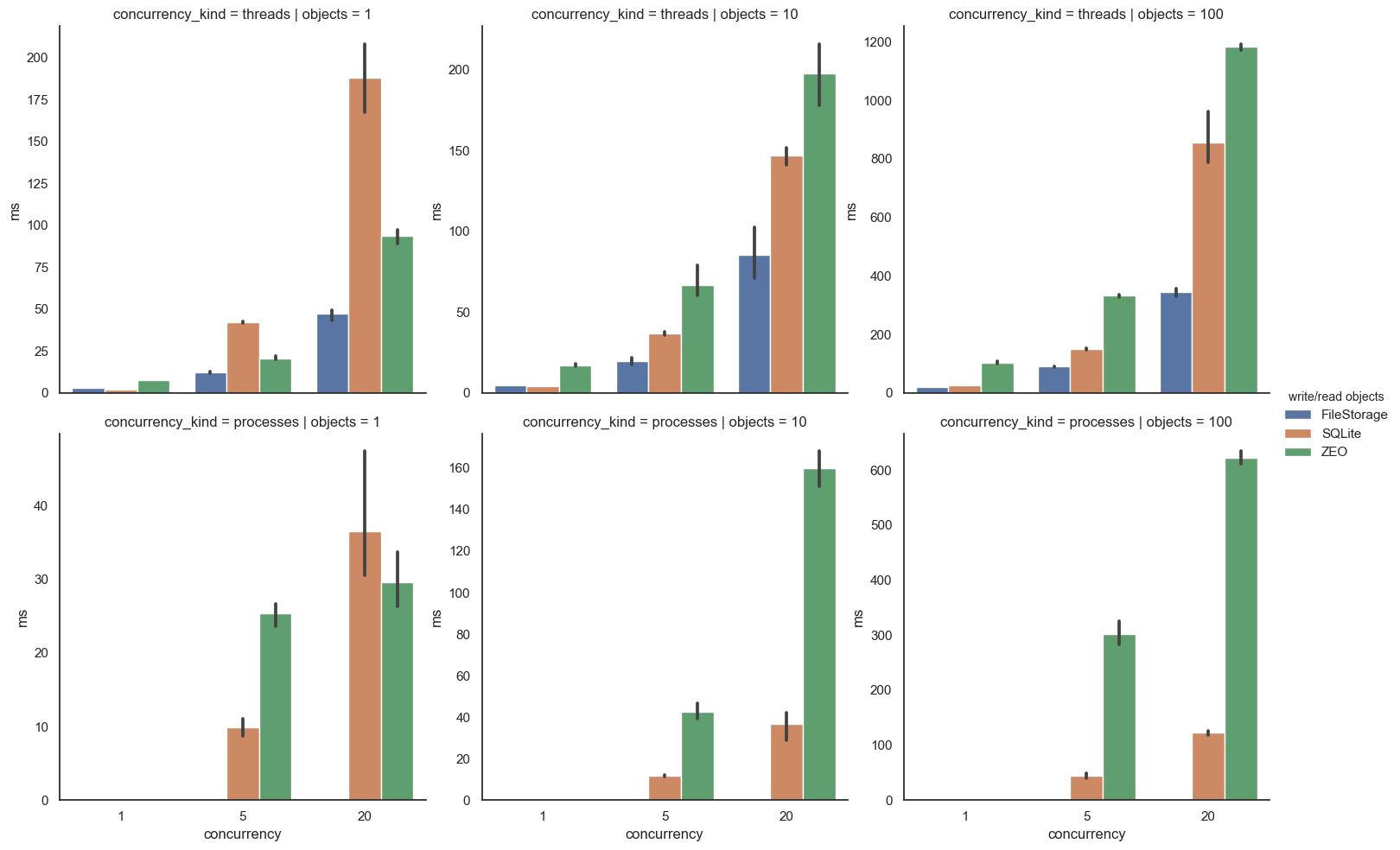
Writing and then reading the same set of objects is more of a mixed
bag, especially where threads are combined and transaction sizes
are small. FileStorage usually wins, possibly thanks to its
append-only file format. SQLite holds its own against ZEO, except
when transaction sizes are small. This is probably an artifact of
the dual connections (one read, one write) RelStorage requires to
implement MVCC.
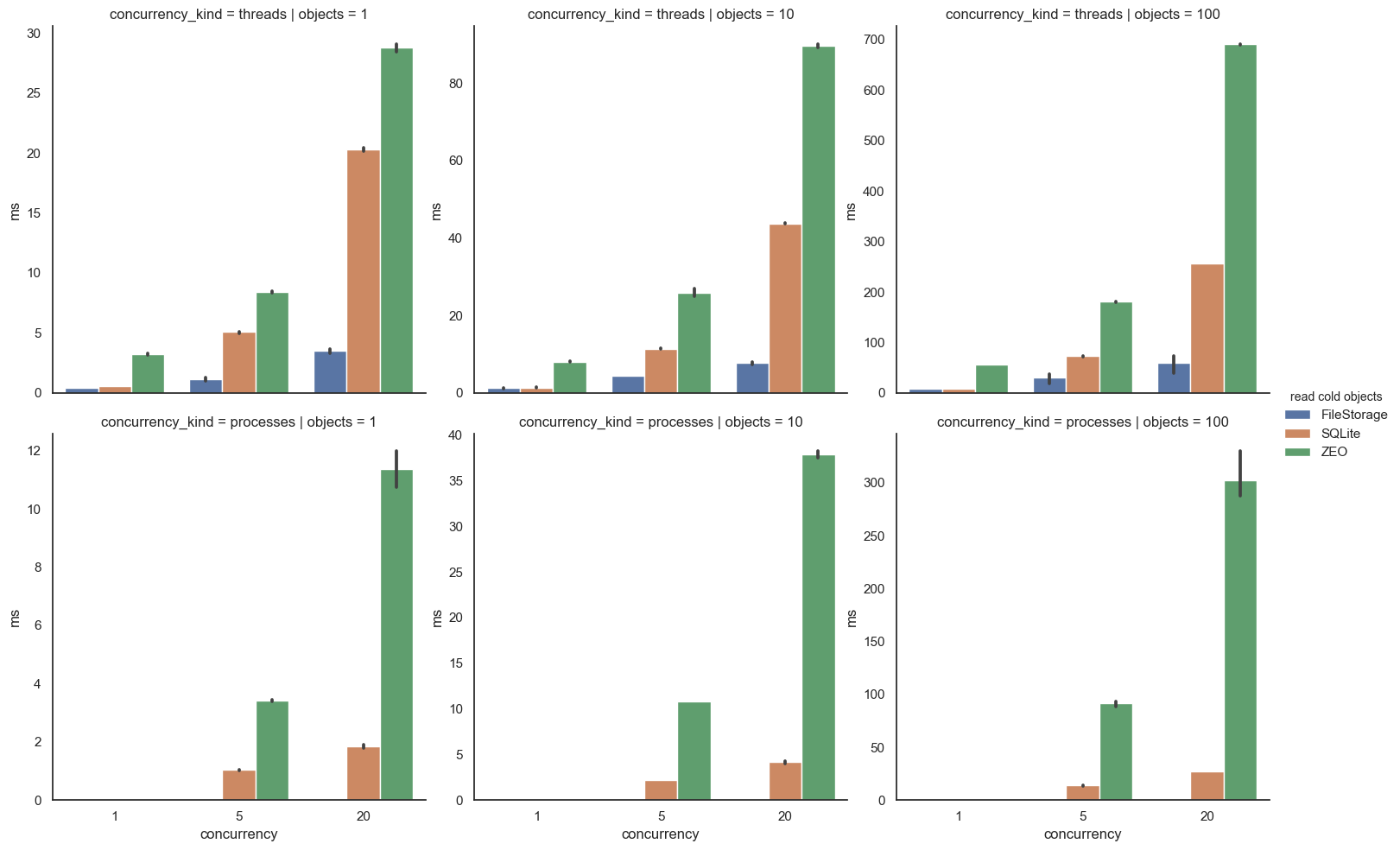
Finally, reading objects. SQLite outperforms ZEO (possibly thanks
to not needing a network round-trip), but FileStorage usually wins.
The best RelStorage can do is tie. For direct reading of objects,
it’s hard to beat FileStorage’s in-memory index of exact disk
offsets. SQLite has to traverse a BTree structure within the
database file.
Q: How do I perform backups of a SQLite RelStorage?
A: (This information is current for RelStorage 3.0 through at least
3.3.)
In general, the simplest and safest way to create a backup of a
SQLite RelStorage is to stop all applications that are using the
database. Then, simply copy the data-dir (and, if configured,
the shared-blob-dir) contents.
If applications cannot be stopped and may be writing to the
database, then it’s important to understand a bit about the
structure of the data-dir. Inside it will be two SQLite3
databases: main and oids. It’s critical to first backup the
main database, and after that backup the oids. If that’s
not done, then using a restored database could result in
re-allocating already used OIDs; that can have many adverse
consequences including errors and data loss.
Transactions against the OID database are always atomic and always
run ahead of transactions against the main database, so an OID
database “from the future” is acceptable, but one from the past is
not. (The worst outcome of an OID database from the future is a gap
in OID values going forward.) Note that not all transactions will
use the OID database, so the timestamp on the file may not, in
fact, be ahead of the timestamp of the main files.
Backing up a SQLite database that’s in use can be accomplished with
the VACUUMINTO...<filename> SQL command in SQLite 3.27 or later, or you may use
a tool that exposes the online backup API, such as the .backup
command of the SQLite shell.
Caution
Attempting file-level copies of a database that’s in
use may result in invalid copies, unless a filesystem
that can perform consistent snapshots is in use and
the backup is performed from such a snapshot.
Q: What if I didn’t back up the OID database?
The OID database, like the main database, is always
auto-created. If the OID database file is missing, or from the
past, and the main database is opened for write transactions, new
objects may get duplicate OIDs. It would be necessary to update the
OID database with the maximum used OID in the main database in
order to prevent this. This can be done by using zodbconvert to
copy the transactions to a new database, or it could be done
manually with SQL queries.